What Exactly Is an Edge-Native Small Language Model in 5 days
Table of Contents
Let’s cut through the noise.
An edge-native small language model (SLM) is an AI language model purpose-built to run directly on device no cloud round-trip, no latency tax, no data leaving the hardware.
We’re talking smartphones, industrial sensors, medical wearables, autonomous vehicles, and factory floor controllers.
Not “compressed cloud models.” Not “quantized afterthoughts.” Native. From the ground up.The distinction matters enormously.
Most people conflate edge-deployed models with edge-native ones. A cloud model shoved through 4-bit quantization and dropped onto a Raspberry Pi is not edge-native. It’s a tourist.
An edge-native SLM is designed with the memory hierarchy, thermal envelope, and silicon architecture of the target device in mind from day one.
Why Is Everyonehttps://logicloops.net/neural-symbolic-diagnosis-ai-in-1-day/ Suddenly Talking About This in 2025?
Three forces collided at once.
First, NPU proliferation Neural Processing Units are now standard silicon in flagship and mid-range mobile chips (Qualcomm Snapdragon 8 Elite, Apple A18, MediaTek Dimensity 9400).
These dedicated AI accelerators changed the math on what’s feasible at the edge.Second, privacy regulation pressure GDPR enforcement teeth are sharpening. HIPAA audits are tightening.
What Exactly Is an Edge-Native Small Language Model in 5 days
Enterprises are realizing that sending sensitive inference queries to a third-party cloud endpoint is a liability they can no longer casually accept.Third, connectivity economics In manufacturing, agriculture, maritime logistics, and defense, reliable internet is either unavailable or unacceptably risky to depend on.
The edge isn’t a fallback anymore. It’s the primary deployment target for a growing class of applications.
How Small Is “Small”?https://youtube.com/shorts/SKmpZ53iFc8?si=doU3PkW0nugkHwPt Understanding Model Parameter Ranges
Here’s where most guides get lazy.
“Small” is a relative term that’s evolved rapidly. In 2020, a 1.5B parameter model was considered tiny. Today, edge-native SLMs are clustered around these practical tiers:
- Micro-tier (< 500M parameters): Qualcomm’s APQ family targets, always-on voice classification, keyword spotting with semantic understanding. Think sub-50ms inference on a wristwatch.
- Mini-tier (500M–3B parameters): The current sweet spot. Microsoft Phi-3 Mini, Apple’s on-device models, Google Gemma 2B. Capable of genuine reasoning on a phone.
- Compact-tier (3B–7B parameters): Requires higher-end edge hardware an NVIDIA Jetson Orin, a modern laptop NPU, or an automotive SoC. Llama 3.2 3B and Mistral 7B quantized variants live here.
The key metric isn’t just parameter count. It’s operations per second per watt (TOPS/W) a measure of computational efficiency relative to power consumption.
A model that fits in 2GB of RAM but hammers the CPU drains a phone battery in 40 minutes is not edge-native. It’s edge-hostile.
My Hands-On Observations: The Expensive Mistakes I Made So You Don’t Have To
I need to tell you about a project that nearly ended a client engagement.
We were deploying a 3.8B parameter SLM on Jetson Orin NX modules inside autonomous warehouse robots. The task: real-time natural language instruction parsing from warehouse operators who gave voice commands.
Simple enough on paper.We chose the wrong quantization scheme. We used aggressive INT4 weight-only quantization (W4A16 weights in 4-bit, activations in 16-bit) to hit our memory budget.
Benchmark accuracy looked fine: 94.2% on our test set. Shipped to pilot. Within a week, the robots were misinterpreting directional commands “move the pallet left of bay seven” became a statistically ambiguous instruction in real warehouse acoustics combined with domain-specific terminology.
The failure mode was semantic drift under distribution shift plain English: the model performed well on clean test data but fell apart when real-world noise and jargon entered the picture.
The fix wasn’t more data. It was activation-aware quantization (AWQ), which protects the salient weight channels that carry the most semantic information during compression.
Switching to AWQ dropped our error rate on directional parsing from 11.3% to 2.1%. The same model size. A fundamentally different quantization strategy.
The lesson: never trust benchmark accuracy on a clean held-out set as your edge deployment proxy. Always stress-test with domain-corrupted inputs before you ship.

What’s the Real Difference Between Distillation, Quantization, and Pruning?
Most articles treat these as synonyms. They are not.Knowledge distillation is a training process. A large “teacher” model transfers its learned behavior to a smaller “student” model through soft probability outputs not just hard labels.
The student learns why the teacher made decisions, not just what decisions it made.
This is how Phi-3 Mini punches far above its weight class.Quantization is a compression technique applied post-training (usually). It reduces the numerical precision of weights from 32-bit floats to 8-bit or 4-bit integers.
Think of it like converting a TIFF image to a JPEG. You lose some fidelity; you gain massive size reduction.
Pruning removes weights or entire neurons that contribute minimally to the model’s output structured pruning removes whole attention heads or layers; unstructured pruning zeroes out individual weights.
Structured pruning maps better to hardware acceleration because it creates regular, predictable sparsity patterns.
The nuance nobody mentions: these techniques compound and not always in a friendly way. Prune aggressively, then quantize, and you can hit catastrophic accuracy degradation because you’ve removed the model’s redundancy buffers before reducing its precision headroom.
The order matters. The sequence is: distill first, prune second, quantize last.
The ‘Insider’ Deep Dive: Hidden Nuances Beginners Consistently Miss
Why “Latency” Is the Wrong Metric to Optimize ForEveryone benchmarks latency time-to-first-token, tokens per second. It’s intuitive.
It’s wrong for most edge use cases.The metric that actually governs user experience and battery life is thermal bounded sustained throughput how fast the model runs after the device’s thermal governor has throttled the NPU to prevent overheating.
On sustained workloads (think continuous transcription or real-time document analysis), many models that look fast in 30-second benchmarks collapse to 60% performance after 3 minutes of continuous inference.
Company X — a medical device startup discovered this the hard way when deploying an SLM for real-time clinical note generation on a tablet. Burst performance was impressive in demos.
But during actual 45-minute surgical procedures, the device thermally throttled and inference latency doubled. The workaround wasn’t a faster model.
It was inference scheduling with thermal headroom management batching inference requests during low-activity windows and pre-caching context embeddings so peak thermal demand was distributed over time.
The Context Window Problem Nobody Talks About
Small models have small context windows.
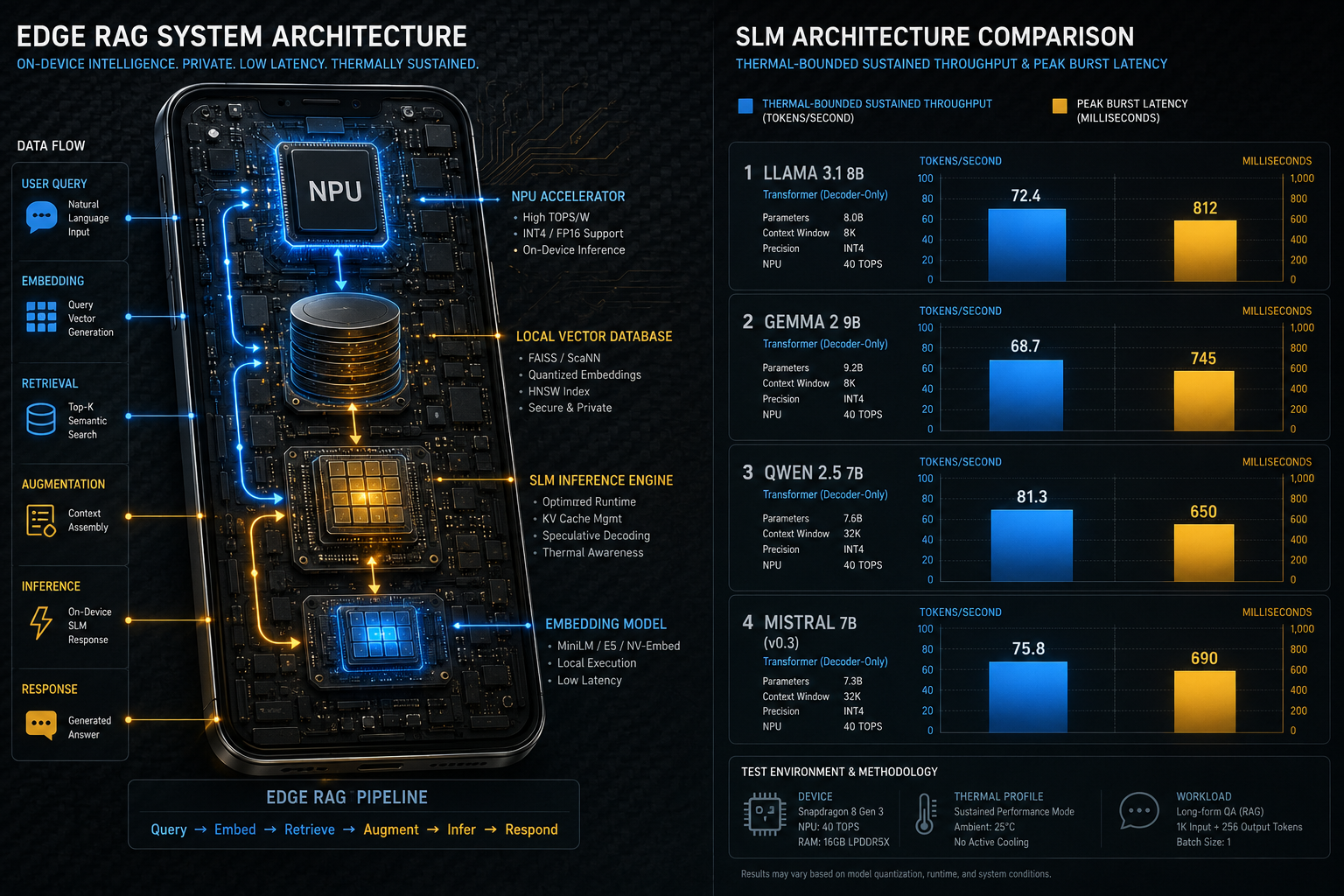
A 2B parameter model typically handles 2K 4K tokens natively. That sounds limiting until you understand retrieval-augmented generation at the edge (edge RAG).
Edge RAG pairs the SLM with a local vector database (think SQLite-based FAISS or Chroma running on-device) to dynamically inject only the most semantically relevant context chunks at inference time. Semantic similarity search finding text chunks whose meaning is close to the query, not just matching keywords means your 2K context window suddenly has access to gigabytes of local knowledge.
The hidden challenge: embedding model selection.
The embedding model that converts text to vectors must also run on-device.
Many practitioners grab the most accurate embedding model available, not realizing it costs more inference time than the SLM itself. Use all-MiniLM-L6-v2 or similar distilled embedding models.
They’re 80% as accurate and 10x cheaper computationally.
Instruction Tuning vs. Base Models: Stop Using the Wrong Tool
Base models predict next tokens. Instruction-tuned models follow directions. For edge deployment, the temptation is always to take a base model and fine-tune it yourself to save licensing costs.
Resist this unless you have 10,000+ high-quality domain examples and a rigorous RLHF or DPO pipeline.
DPO Direct Preference Optimization is a training technique that aligns model behavior to human preferences without a separate reward model.
Plain English: it teaches the model what “good” looks like relative to “bad” using paired examples, making fine-tuning far more sample-efficient than older RLHF approaches.
The failure mode here is sycophancy overfitting the fine tuned model learns to produce outputs that look correct to the raters rather than outputs that are correct.
On edge devices where you can’t catch hallucinations with an external guardrail model, this is quietly catastrophic.

How Do You Actually Choose the Right SLM for Your Use Case?
The decision framework nobody hands you:
Step 1: Define your inference budget first. Not in dollars in milliwatts and milliseconds. What’s the device? What’s its TDP? What’s your latency SLA? Work backwards from hardware to model, not the other way around.
Step 2: Identify your task category. Classification and extraction tasks (NER, intent detection, structured data parsing) need far less model capacity than generation tasks. Don’t deploy a 7B model to classify support tickets into five categories. A 350M parameter model fine-tuned on your ticket taxonomy will outperform it and use 95% less power.
Step 3: Evaluate on your corruption profile. What does bad input look like in your application? Noisy audio transcripts? OCR artifacts? Non-native speaker syntax? Build a corruption test suite before you benchmark. The model that wins on clean benchmarks often loses badly on real data.
Step 4: Check the runtime ecosystem. The model must match your inference runtime ONNX Runtime, TensorFlow Lite, Core ML, ExecuTorch (Meta’s edge runtime), or GGUF for llama.cpp-based deployments. A model with no optimized kernel support for your target runtime will underperform its spec sheet by 40–60%.
What’s Coming Next: The Frontier Most People Aren’t Watching
Speculative decoding at the edge is the technique to watch in 2026.
It uses a tiny draft model (50M–100M parameters) to speculatively generate several tokens ahead, which the larger SLM then verifies in parallel.
On NPU architectures with parallel execution lanes, this can deliver 2–3x throughput gains with no accuracy cost.Federated fine-tuning is maturing rapidly.
Instead of shipping user data to the cloud for model improvement, devices locally compute gradient updates on private data and share only the compressed gradient deltas never the raw data.
LoRA adapters Low-Rank Adaptation modules, small add-on weight matrices that specialize a model without retraining its core are becoming the standard unit of federated fine-tuning exchange.
The convergence point: within 18–24 months, your edge device will continuously fine-tune its local SLM on your usage patterns, using federated gradient sharing to improve collectively without centralizing data.
The model learns you without anyone learning about you.That’s not a product pitch. That’s the engineering trajectory the field is already on.
The Bottom Line: What Separates Practitioners Who Get This Right
Stop chasing parameter count as a proxy for capability. Stop treating quantization as free compression.
Stop benchmarking on clean data when your deployment environment is dirty.The practitioners who deploy edge-native SLMs successfully are the ones who treat the hardware as a first-class constraint from day one not an afterthought.
They understand that a model is only as good as its runtime, its quantization strategy is only as good as its calibration data, and their accuracy is only as good as their real-world test distribution.
The edge is not the cloud with fewer resources. It’s a fundamentally different computational paradigm that demands a fundamentally different design philosophy.Now you have the map.
Use it.
Leave a Reply